Google has introduced a groundbreaking large language model (LLM) named VideoPoet, designed to revolutionize video generation. Unlike its predecessors, VideoPoet is a multimodal LLM capable of processing various inputs, including text, images, video, and audio, to generate videos. This model is considered a significant leap in the field of video generation, offering capabilities that go beyond traditional language models.
VideoPoet is equipped with a ‘decoder-only architecture,’ allowing it to produce content for tasks it hasn’t been explicitly trained on. The training process involves two key steps similar to other LLMs: pretraining and task-specific adaptation. During pretraining, the LLM is trained on a diverse set of data encompassing video, audio, images, and text. This pre-trained model serves as the base framework that can be customized for specific video generation tasks.
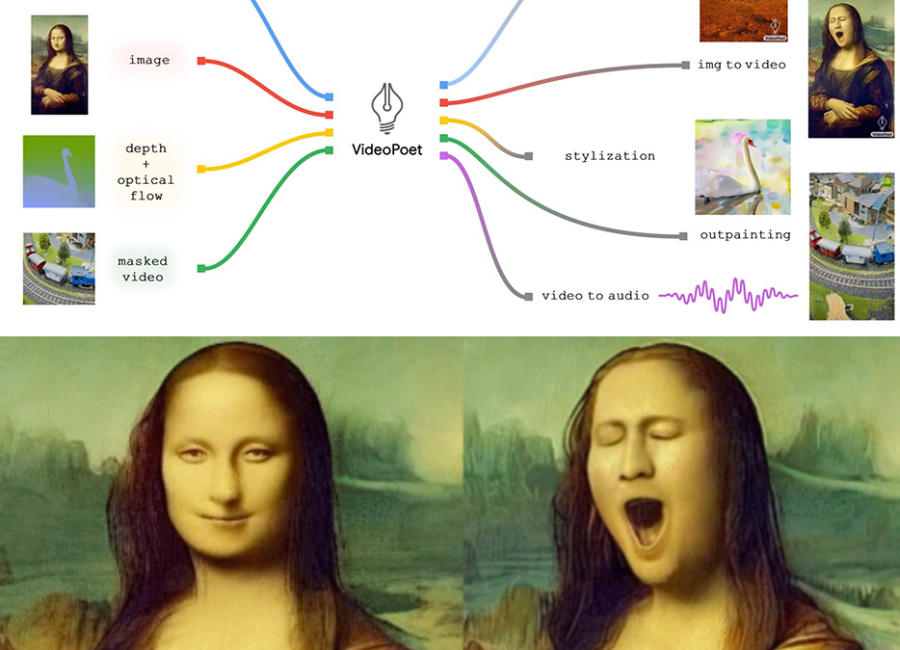
The model’s versatility is highlighted by its success in various video-related tasks, including text-to-video, image-to-video, video inpainting and outpainting, video stylization, and video-to-audio generation. Unlike conventional video models that often use diffusion models introducing noise to training data, VideoPoet integrates multiple video generation capabilities into a unified language model. This integration streamlines the model’s architecture, distinguishing it from models with separately trained components for different tasks.
VideoPoet operates as an autoregressive model, generating output by building upon its previous outputs. It has been trained on diverse modalities using tokenization to convert input text into smaller units known as tokens. Tokenization is crucial for natural language processing, allowing the model to comprehend and analyze human language effectively.
One notable feature of VideoPoet is its ability to create short films by combining various video clips. Researchers demonstrated this capability by instructing Google Bard to write a short screenplay using prompts. VideoPoet then generated a video based on these prompts, and the resulting clips were assembled to produce a short film. This showcases the model’s potential for creative applications, allowing users to experiment with storytelling in a visually compelling manner.
However, VideoPoet currently faces limitations in producing longer videos. Google acknowledges this constraint and proposes a solution: conditioning the last second of videos to predict the next second, thereby extending its video generation capabilities.
The model also exhibits the intriguing ability to manipulate the movement of objects in existing videos. As an example, it can be applied to scenarios such as altering the facial expressions of the Mona Lisa.
The results achieved by VideoPoet underscore the promising potential of large language models in the realm of video generation. The researchers behind this innovative model envision a future where it can support a wide range of ‘any-to-any’ video generation formats, further enhancing its adaptability and usefulness.
While VideoPoet’s release is a notable advancement, there is currently no specific information on its availability or pricing. As the field of multimodal large language models continues to evolve, VideoPoet represents a significant step forward in pushing the boundaries of what is possible in video generation using artificial intelligence.



